Most teams treat documentation as the answer to bad decisions.
Write the rules down. Keep the README updated. Record the ADRs. Explain the patterns clearly enough, and engineers will know what to do. In practice, it rarely works that cleanly.
The problem is not that engineers do not read documentation. The problem is that documentation is optional. Architecture is not.
A constraint shapes behaviour whether people remember why it exists or not. A document only helps the people who know where to find it, take the time to read it, and remember it at the exact moment they need it.
That is the distinction I want to explore here: not documentation versus architecture, but documentation as explanation versus architecture as guidance.
Make decisions discoverable, not just documented
There is a README in almost every project you’ve ever touched. Some of them are outdated. Most of them are incomplete. All of them are optional to read. And yet the moment someone joins a new team or inherits a codebase, that file is where they’re told to start. We have agreed, as an industry, that the most important information about how a system works should live in a place that is not the system itself.
This is the root of a problem that gets misdiagnosed constantly. Teams think they have a documentation problem when they actually have an architecture problem. When the design of a system doesn’t communicate its own rules, you have to explain them somewhere else. And somewhere else is always the first place those rules get lost.
Good architecture does not just support what a system does. It shapes what the system makes easy, obvious, or difficult. When those constraints are built into the codebase, the team does not need to rely on documentation as the only place where the rules exist.
When a layer boundary exists in the code and not just in a diagram on Confluence; when a naming convention is enforced by tooling instead of by habit; when a data flow direction is made explicit through the types and interfaces in the codebase; then the system is doing the documentation.
It tells the next engineer what the previous decisions were by making the intended path easier to follow than the accidental one.
A document can be ignored. A constraint built in the system can’t. If your architecture separates concerns at the right boundaries, a new developer working inside one layer doesn’t need to understand the full picture to make a good local decision. The system guides them. If the architecture doesn’t do that, the system will still guide them, but it will guide them based on whatever patterns were easiest to follow, not whatever was intentional.
Rules embedded, not explained
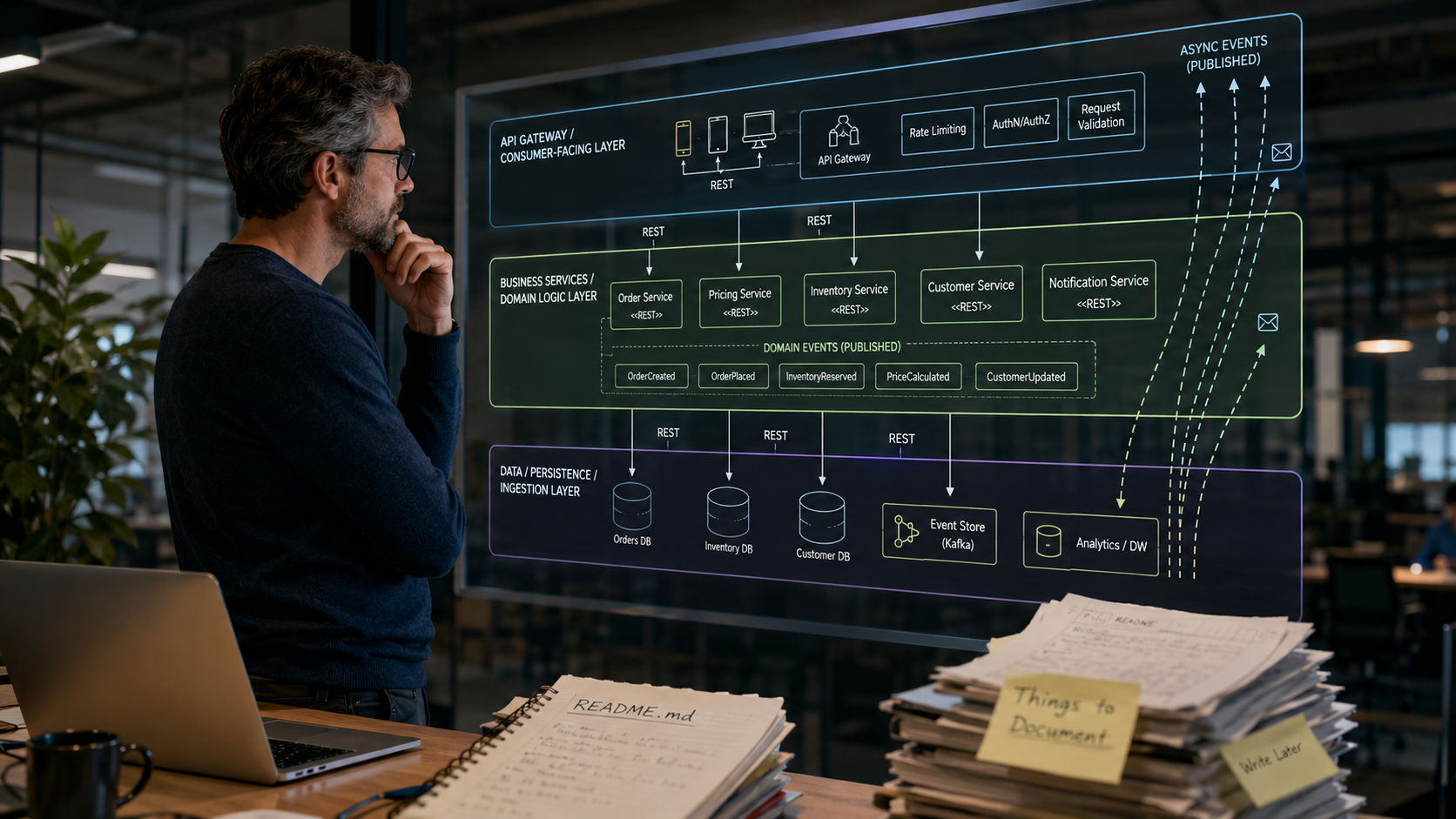
Let me give you a real example. At Carlsberg, we built several systems around four explicit layers: an API gateway responsible for authentication and entry points, services responsible for routing and aggregation, a business services layer owning domain logic, and a data layer responsible for persistence and ingestion.
The design was not especially innovative, and that is part of the point. Its value was not in being clever. Its value was in being easy to follow.
Shared libraries and internal utilities made the rules visible in the codebase: how services communicated, where domain logic belonged, how errors were handled, and how logs were structured. A new developer did not need to read a long document to understand where a new service should live or which mechanisms were available. The system gave them a path.
That mattered as the team grew from a small group of developers to a much larger engineering organisation. Developers did not need to ask where something belonged. The structure made that clear.
Making the wrong decision a hard move

Here’s a simpler version of the same principle. Imagine two teams building a backend application that integrates with third-party APIs.
In the first team’s codebase, HTTP calls are scattered across service classes. Some are wrapped in error-handling logic. Some aren’t. Some use a shared client, some initialize their own. When a new engineer needs to add another integration, they look at the existing examples, make their best guess about which pattern to follow, and move on.
In the second team’s codebase, all outgoing calls go through a dedicated infrastructure layer. The interfaces are typed. Error contracts are consistent. Retry and timeout behavior is centralized. Adding a new integration means implementing the interface and letting the rest of the infrastructure handle itself.
The first team has documentation explaining how external calls should work. The second team has architecture that makes the wrong approach difficult to take by accident. One of them needs a README. The other one doesn’t.
The Expert Dependency
The real test for whether an architecture is doing its job isn’t a design review or a post-mortem. It’s a thought experiment: if you put a capable senior engineer on this codebase today, with no prior context, no onboarding session, and no one to ask, could they make the right call? Not just a technically valid call, but one that fits how the system is supposed to evolve?
If the answer is no, too much of the architecture still lives outside the system, in someone’s head, or in a document that will drift from reality as soon as the next sprint starts. At some point it will influence a decision, and that decision will be made without the relevant information. This is where systems start drifting quietly: not because people are careless, but because the design does not give them enough information to make the right local decision.
And in the end, this is the practical implication: an architecture that doesn’t communicate its own rules isn’t just a technical problem. It increases the risk of failure. Every time someone touches that system without the full context, the chance of a bad decision grows. And it’s understandable: people making those decisions rarely know what they are missing.
And that, for me, is not a documentation gap. It’s a design gap.
The system still decides
Of course, not every team gets the architecture right from the start. Most do not. Deadlines, uncertainty, legacy constraints, and incomplete knowledge all shape the first version of a system.
But when those decisions are left implicit, the system still decides. It just does so silently, on behalf of whoever touches it next. That is where deferred architecture decisions start compounding.
In Part 2 of this article, we’ll look at what deferred architecture decisions cost and why the consequences always arrive sooner than expected.