
The most expensive sentence in software is “we’ll clean it up later.”
In Part 1, I argued that good architecture guides the next decision by making the intended path easier to follow than the accidental one. The natural follow-up is what happens when you don’t make that decision at all. When you defer it.
Here is the trap. We talk about deferring an architecture decision as if “later” is a real place we will eventually get to. It usually is not. A deferred decision is not just a postponed decision. It is a delegated one, handed off silently to whoever touches the code next, usually with less context than you have right now.
A deferred decision is not a postponed decision
“Later” is a fiction. The moment you decline to decide where something belongs, how a boundary should work, or which pattern an integration should follow, the system starts deciding for you. Not eventually. Immediately.
And the default is never the option you would have chosen on purpose. The default is whatever path is easiest to follow. In Part 1, I made the point that a system without intentional constraints still guides people, just based on whichever patterns are easiest to copy. Deferral is the same mechanism seen from the other side. You think you have left the question open. The codebase has already started answering it.
So the decision still gets made. The difference is that it is made without an owner, without a rationale, and without a record. Nobody decided it, which means nobody can revisit it, because there is nothing to point at.
How the cost compounds
This is where deferral stops being a code-quality footnote and starts being structural.
Picture a team adding their first third-party integration under deadline. They inline an assumption: the external call lives directly inside a service class, the response contract is trusted as-is, there’s no real boundary between “our domain” and “their API.” It works. It ships. It was never decided, it was just the shortest path to getting the feature out.
Then the second engineer arrives to add the next integration. They do exactly what Part 1 predicts: they look at the existing example and follow it, because the system presents it as the path.
They are not being careless. They are being reasonable. But they are unknowingly following something that started from the wrong assumptions. All of a sudden, the shortcut has quietly become the convention.
And it gets worse. A third engineer builds logic on top of that integration. Another test suite starts relying on the same response shape. A downstream component assumes that the external API contract is safe to use directly. Each new decision inherits the unstated one underneath it.
None of them know they are standing on a choice nobody made.
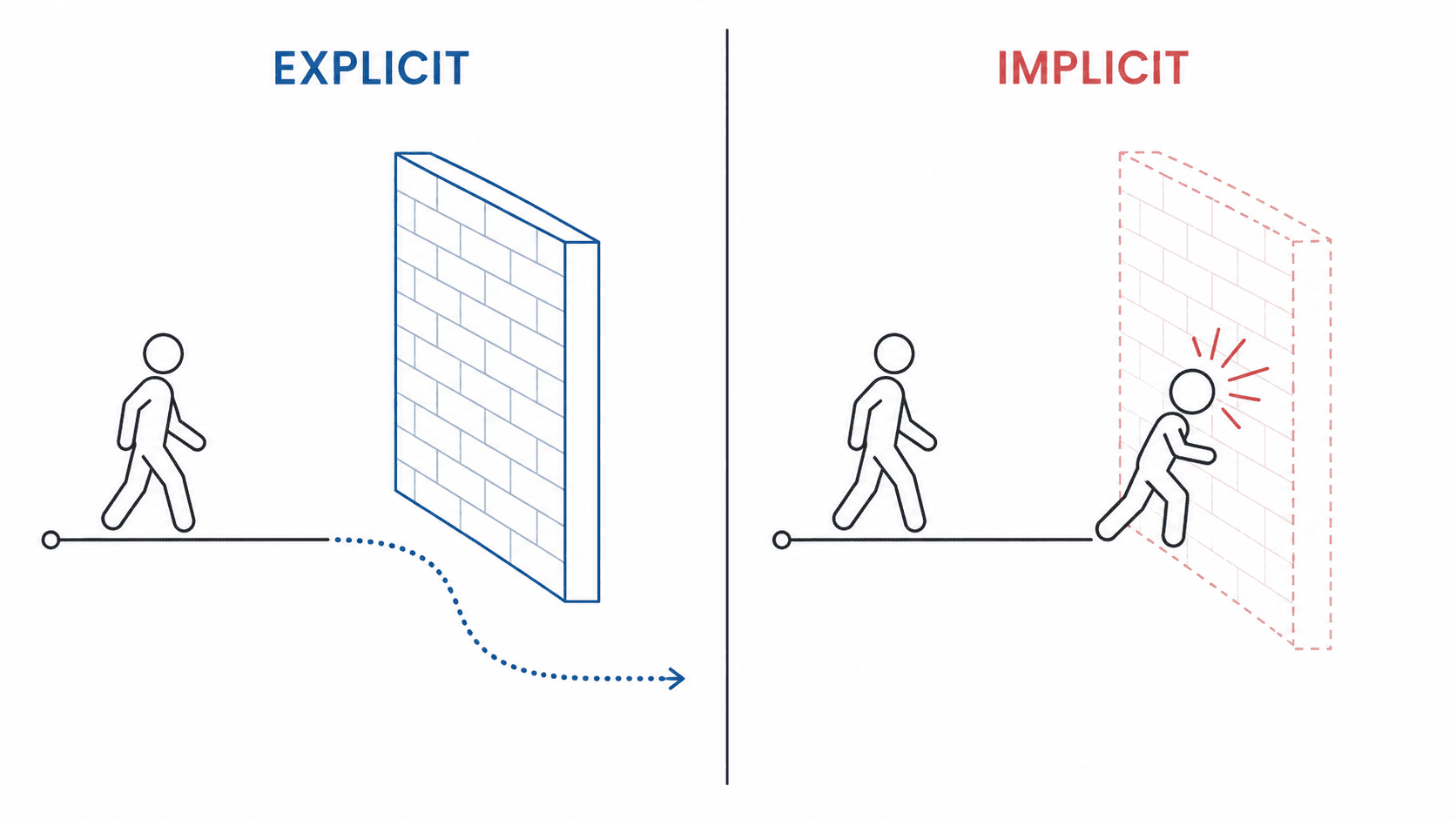
That is the difference between an explicit constraint and an implicit one.
An explicit constraint is a wall you can see. You can route around it, and routing around it is cheaper because you knew it was there.
An implicit decision is a wall you discover by walking into it, usually at the worst possible time, usually with a feature half-built against it.
The visible symptom appears much later: velocity decays, and nobody can name the cause. There’s no failed design review to blame, and no bad ADR to revise. The decision that’s slowing everyone down was never recorded, so there is nothing to point at.
The team starts describing the codebase with words like “fragile” and “hard to maintain”, which are often just the names we give to accumulated decisions we can no longer see.
The interest, not the principal
We often reach for “technical debt” here, but the metaphor is usually used too loosely. It’s worth being precise, because the precise version is the whole argument.
The messy code is the principal. And the principal, on its own, is often cheap. A single ugly integration you can see is a bounded problem: you find it, you fix it, you move on.
The interest is everything built correctly on top of an incorrect implicit decision. That is the part that compounds.
Every feature that assumed the wrong boundary was right. Every test written against it, every downstream component that trusts it: those are the accrued interest, and they grow on their own even when no one realizes they are taking on more debt.
This is why, as I claimed at the end of Part 1, the consequences arrive sooner than expected. Compounding is not linear, and we are bad at feeling it coming.
The bill, when it lands, is rarely “fix this one piece of code.” It is “unwind everything we built assuming this code was right.” That second number is the one nobody budgeted for.
Why this is a business risk, not a code-quality issue
Up to here, this may sound like an engineering concern. It is not, or at least not only. This is the part that should matter to the people who never open the codebase, because the effects show up in business terms long before anyone agrees on the technical cause.
Delivery slows with no diagnosable reason
The roadmap quietly slips. Estimates inflate. Nobody can explain why the same kind of feature that took a week last year now takes a month, because the cause is distributed across a hundred invisible decisions.
Key-person risk increases
The missing decisions live in the heads of whoever was there when they were made. The organisation becomes dependent on memory. When that person goes on leave, changes team, or leaves entirely, the context leaves with them.
The cost of change rises
Every new feature pays the interest before it delivers value. Over time, more of the team’s capacity goes into working around the past than building the future.
The risk of failure goes up
This is the point I raised in Part 1: people keep making high-stakes decisions without the context to make them well, and they rarely know what they are missing.
Put together, deferred architecture is an unhedged liability. It sits off the books. It appears on no status report and in no sprint review, right up until it is large enough that it appears in all of them at once.
By then it is not a refactor. It is a budget line.
You cannot avoid deciding, only avoid deciding well
None of this is an argument for getting the architecture perfect up front. As I said in Part 1, most teams don’t, and they can’t. Deadlines are real. Requirements are uncertain. Legacy constrains you. You will make provisional calls with incomplete information, and that is fine.
The mistake is not making a provisional decision. The mistake is making it invisibly.
The move is to make the provisional decision explicit and cheap to reverse. Encode even a temporary choice as a visible constraint: a named boundary, a typed interface, a single place where the shortcut lives. That way, the next engineer can see that it is a decision, not a law of nature.
You are not committing to it forever. You are leaving a marker that says “someone chose this, on purpose, and here is the seam where you change it.”
Visible seams can be revisited. Invisible ones can only be discovered, and they are usually discovered the expensive way.
Closing: architecture is writing to the future
Architecture is a form of writing to the future.
And the audience is not the well-rested engineer in the design review with the full diagram on screen. The audience is someone under pressure, six months from now, with a deadline and no time to read the docs, trying to make one good decision inside a system they didn’t build.
Good architecture writes that person a clear instruction by making the right path the easy one. A deferred decision writes them nothing, and then bills them for the silence.
That is the through-line across both parts.
Good architecture guides the next decision. Deferred architecture still decides, just silently, on behalf of whoever comes next.
And it sends the invoice sooner than anyone expects.